
爬蟲爬取網站之家,【Python爬蟲】用Python爬取娛樂圈排行榜數據
??想關注你的愛豆最近在娛樂圈發展的怎么樣嗎?本文和你一起爬取娛樂圈的排行榜數據,來看看你的愛豆現在排名變化情況,有幾次登頂,幾次進了前十名呀。 PS:在下一篇文章中分析排行榜的動態變化趨勢,并繪制成動態條形圖和折線圖。 ?? 一、網站

基于python爬取豆瓣圖書信息,Python爬蟲入門 | 7 分類爬取豆瓣電影,解決動態加載問題
? 比如我們今天的案例,豆瓣電影分類頁面。根本沒有什么翻頁,需要點擊“加載更多”新的電影信息,前面的黑科技瞬間被秒…… 基于python爬取豆瓣圖書信息,? 又比如知乎關注的人列表頁面: ? 我復制了其中兩個人昵稱的 xpath: //*[@id&#

爬蟲怎樣爬取網站數據,scrapy爬蟲入門:爬取《id97》電影
id97下電影 我們本次要爬取的網站:http://www.id97.com/movie 爬蟲怎樣爬取網站數據、1、打開終端:scrapy startproject movieprject 2、scrapy genspider movie 形成的目錄結構如下: scrapyd。3、setting里面設置 第19行: USER_AGENT = '

螞蟻短租與小豬哪個好,Python爬蟲入門 | 5 爬取小豬短租租房信息
小豬短租是一個租房網站,上面有很多優質的民宿出租信息,下面我們以成都地區的租房信息為例,來嘗試爬取這些數據。 小豬短租(成都)頁面:http://cd.xiaozhu.com/ ? 1.爬取租房標題 按照慣例,先來爬下標題試試水,找到標

如何用爬蟲抓取數據,爬蟲實戰入門級教學(數據爬取->數據分析->數據存儲)
爬蟲實戰入門級教學(數據爬取->數據分析->數據存儲) 天天刷題好累哦,來一期簡單舒適的爬蟲學習,小試牛刀(僅供學習交流,不足之處還請指正) 文章講的比較細比較啰嗦,適合未接觸過爬蟲的新手,需要源碼可直

爬蟲爬取網站之家,爬蟲爬取王者榮耀 英雄故事 和技能
初識爬蟲爬取王者榮耀英雄故事和技能 爬取王者榮耀英雄故事和技能 源碼奉上 import requests import re import os from lxml import etree if __name__ == '__main__':#創建一個文件夾wz#打算爬取皮膚圖片,銘文,出裝等 先創建一個文件夾使用i
爬蟲爬取網站之家,爬蟲——爬取MOOC課程資源
step1:瀏覽需要爬取資源的主頁,找到鏈接 每一節課的id號依此遞增 step2:ctrl+shift+C 查看源碼,刷新頁面(才能出現視頻資源) 刷新前: 刷新后: step3:在源代碼中查找原視頻鏈接所在位置 爬蟲爬取網站之

python爬蟲爬取小說代碼,爬蟲實戰|從筆趣閣爬取書籍并簡單保存
最近在看崔慶才那本經典的爬蟲開發書籍,之前雖然看過一點視頻,但是與書籍相比還是書籍更加成體系,讓我對知識有一個宏觀的把控。目前已經看了前四章,了解了一些基礎知識和如何解析數據的方法,但是對于數據的保存還不是很清楚。話不多說&#x

php多線程爬蟲,Python多線程爬蟲之二:爬取王者榮耀高清壁紙(多線程)
一、項目分析 1、查詢爬取網址 robots 權限 1、王者榮耀官網:https://pvp.qq.com/ 2、訪問王者榮耀官網 rbots 權限: https://pvp.qq.com/robots.txt,確定此網站沒有設置 robots 權限,即證明此網站數據可以爬取。 2、查詢主頁和詳情頁面的關系 高

scrapy爬蟲,Python Scrapy簡單爬蟲-爬取澳洲藥店,代購黨的福音
身在澳洲,近期和ld決定開始做代購,一拍即合之后開始準備工作。眾所周知,澳洲值得買的也就那么點東西,奶粉、UGG、各種保健品,其中奶粉價格基本萬年不變,但是UGG和保健品的價格變化可能會比較大。所以,打算寫個爬蟲解決一下經

爬蟲怎樣爬取網站數據,【爬蟲入門】【正則表達式】【同步】爬取人人車車輛信息1.0
# 爬取人人車車車輛信息。from urllib.request import urlopen from urllib.error import HTTPErrorimport re, sqlite3class RRCSpider(object):"""人人車爬蟲類"""def __init__(self):passdef get_list_html(self, page_num):"""獲取列

爬蟲快速入門,菜雞爬蟲入門——爬取圖片
爬取圖片的一般步驟 1.先聲明一個存放圖片的地址(path) 2圖片是二進制格式,如何把二進制保存為圖片呢? 2.1 用到with open()先打開文件 2.2 r.content表示返回內容的二進制格式 用f.write(r.content)將返回的二進制寫入文件中 代碼
python爬取網易云音樂的代碼,Python爬蟲——教你js逆向爬取網易云評論
大家好!我是霖hero 正所謂條條道路通羅馬,上次我們使用了Selenium自動化工具來爬取網易云的音樂評論,Selenium自動化工具可以驅動瀏覽器執行特定的動作,獲得瀏覽器當前呈現的頁面的源代碼,做到可見即可爬,但需要等網頁完全加載完&#

python爬蟲爬取圖片,Python爬蟲爬取王者榮耀英雄人物高清圖片
Python爬蟲爬取王者榮耀英雄人物高清圖片 實現效果: 網頁分析 python爬蟲爬取圖片,從第一個網頁中,獲取每個英雄頭像點擊后進入的新網頁地址,即a標簽的 href 屬性值: 劃線部分的網址是需要拼接的 在每個英雄的具體網頁內,爬取英雄皮膚圖片

爬蟲實例解析,爬蟲實例3:Python實時爬取新浪熱搜榜
? ? ? ? 因為了解到新浪熱搜榜每分鐘都會更新,所以寫的是每分鐘爬取一次的死循環,按照日期為格式創建路徑,將 爬取的信息按照時間順序 輸出到excel。 步驟: 1、在瀏覽器中,用F12分析熱搜榜頁面的html標簽結構,觀察有無分頁情況、分

爬取,30 爬蟲 - 爬取內涵段子網站案例
現在擁有了正則表達式這把神兵利器,我們就可以進行對爬取到的全部網頁源代碼進行篩選了。 下面我們一起嘗試一下爬取內涵段子網站: http://www.neihan8.com/article/list_5_1.html 打開之后,不難看到里面一個一個灰常有內涵的段子,當你進行翻頁的

python爬取豆瓣top250,Python-爬蟲(Scrapy爬蟲框架,爬取豆瓣讀書和評分)
文章目錄1.Scrapy注意點2. Scrapy爬取豆瓣讀書和評分代碼部分數據定義items.py爬蟲部分spiders/book.py數據存儲部分pipelines.py啟動爬蟲執行cmd命令 start.py 1.Scrapy注意點 Scrapy是爬蟲框架。 它分為一下部分,其中引擎是核心 Scrapy Engine(引擎):負責spider、lt
python爬取電影,多線程爬蟲爬取電影天堂資源
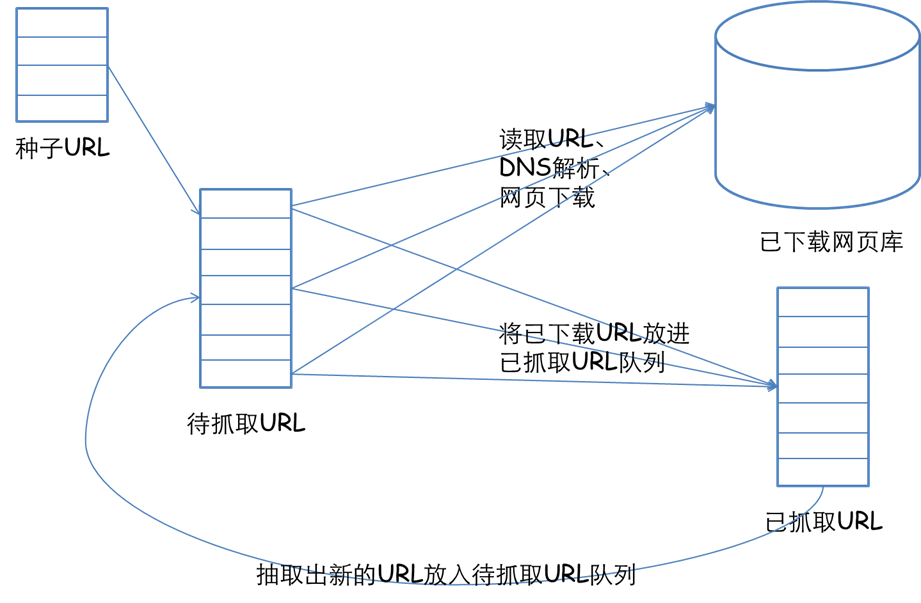
先來簡單介紹一下,網絡爬蟲的基本實現原理吧。一個爬蟲首先要給它一個起點,所以需要精心選取一些URL作為起點,然后我們的爬蟲從這些起點出發,抓取并解析所抓取到的頁面,將所需要的信息提取出來,同時獲得的新的URL插入到隊列中作為下

網站爬取工具,爬取某電影網站(未寫完)
1 import requests 2 import bs4 3 import lxml 4 import re 5 import time 6 from bs4 import BeautifulSoup 7 #網站 8 url = 'https://www.88ys.cc' 9 #電影或電視劇的名字 10 film = '家有女友' 11 #代理ip 12 proxy='120.24.245.33:168

圖片爬蟲,爬取淘寶女郎的照片-寫給初步入門爬蟲的讀者
爬取淘寶女郎照片-寫給初步入門爬蟲的讀者 ??? 要爬取的照片示例: 圖片爬蟲、python2.7爬蟲代碼如下: #coding=utf-8 import urllib2mmurl = "https://mm.taobao.com/json/request_top_list.htm?type=0&page=" # Taobao MM i =