豆瓣电影Top250信息爬取并保存到excel文件中
豆瓣电影Top250信息爬取并保存到excel文件中
豆瓣电影Top250下载并保存到excel文件中
- 效果图
- 前言
- 确定目标网页url
- 爬取过程
- 导入相关库
- 页面内容的获取
- 页面解析
- 数据提取
- 主函数的编写
- 函数调用
- 数据存储
- 完整代码
- 结语
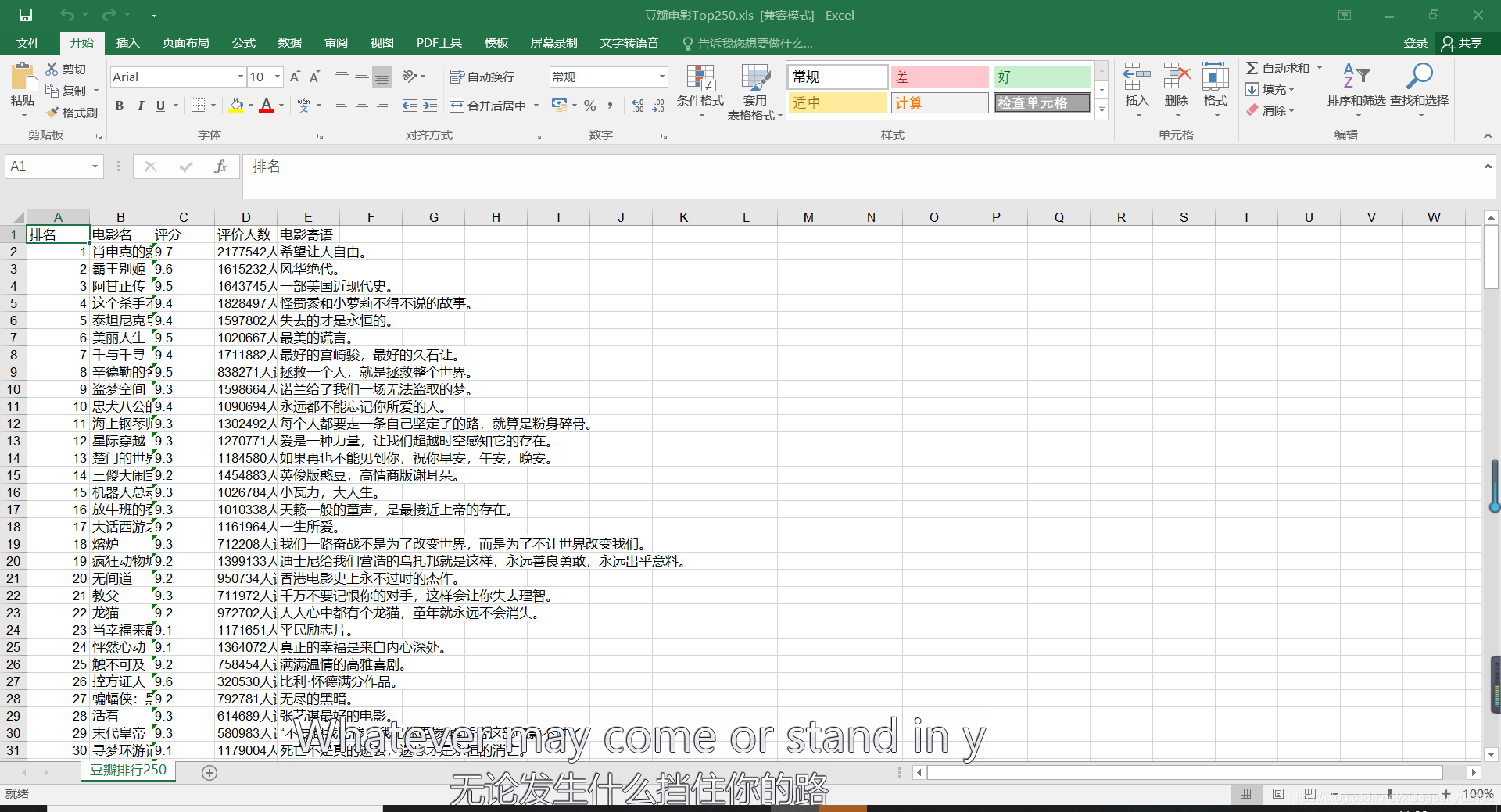
效果图
python爬取豆瓣影评,话不多说,先上存储为excel文件后的效果图,这里只是简单的将爬取到的数据保存到文件中,没有对表格数据进行标准化处理。因为这涉及到另一个python用来处理表格的库,在这里就不过多的说明,稍后会有相关的文章涉及。
前言
对于豆瓣电影Top250的爬取是相对来说很简单的,尤其是对于新手来说,用该页面来当作爬虫的上手练习项目,是入坑爬虫的首选,很多爬虫初学者都会选择该项目作为入门练习。一直以来,本人都很少用函数式编程的方法来写爬虫代码,总是习惯于用简单的一条线式的编写方式,在这篇文章中采用的是函数式的编程方式。同时也涉及到用python来将数据写入excel表格,初步了解相关的用法。
确定目标网页url
爬虫处理excel数据,通过查看网页源代码,我们知道该网页数据是静态数据,没有任何反爬机制,这也是前面为什么说作为入门爬虫的很好练手网页。点击鼠标右键,选择查看网页源代码,会弹出该页面的原始HTML代码,这时候我们按住CTRL+F,调出搜索框,搜索我们在浏览器中看到的数据。
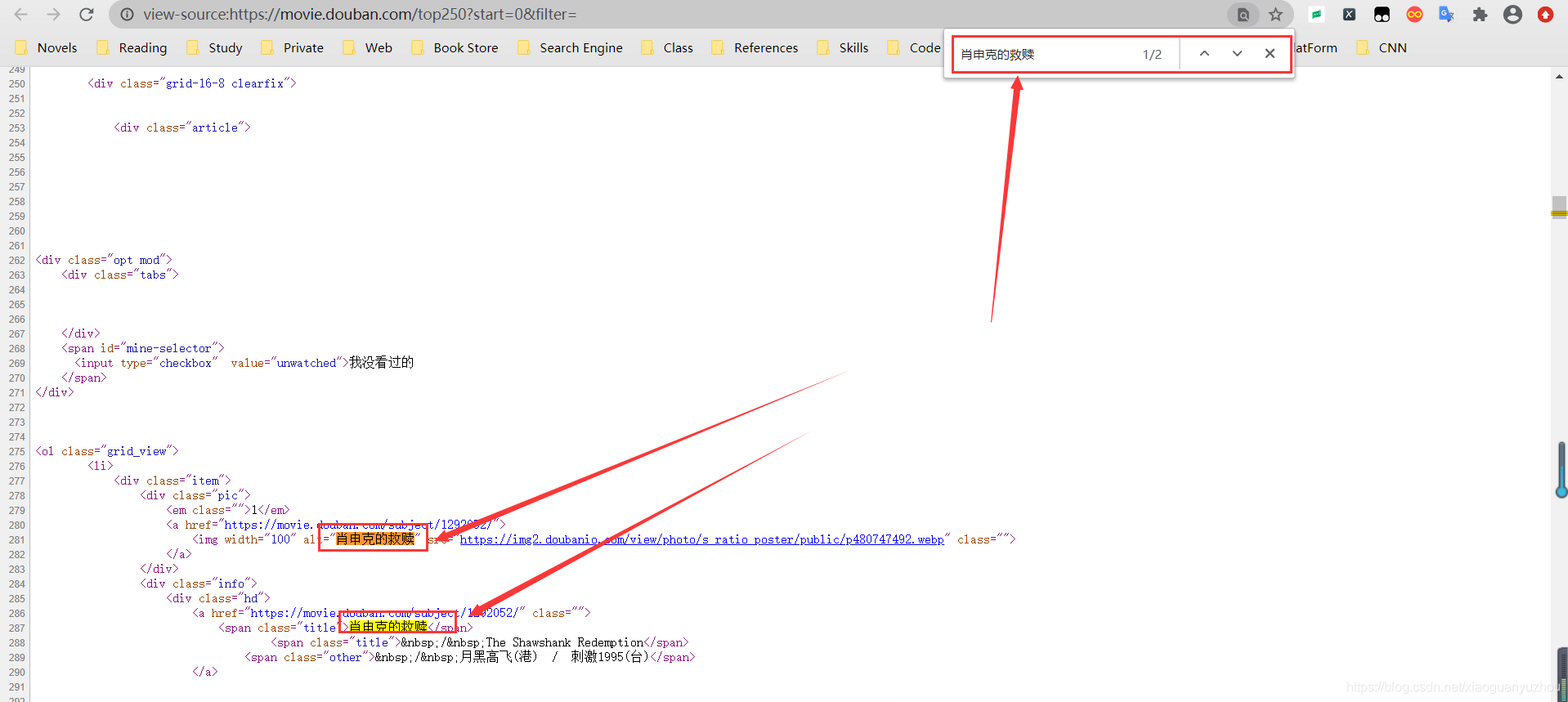
再搜索其它电影的名字,同样也能搜索到,因此我们确定该页面就是静态网页,其目标url就是网址栏中的网址,如下图,如此我们就确定了索所要爬取的页面的url。
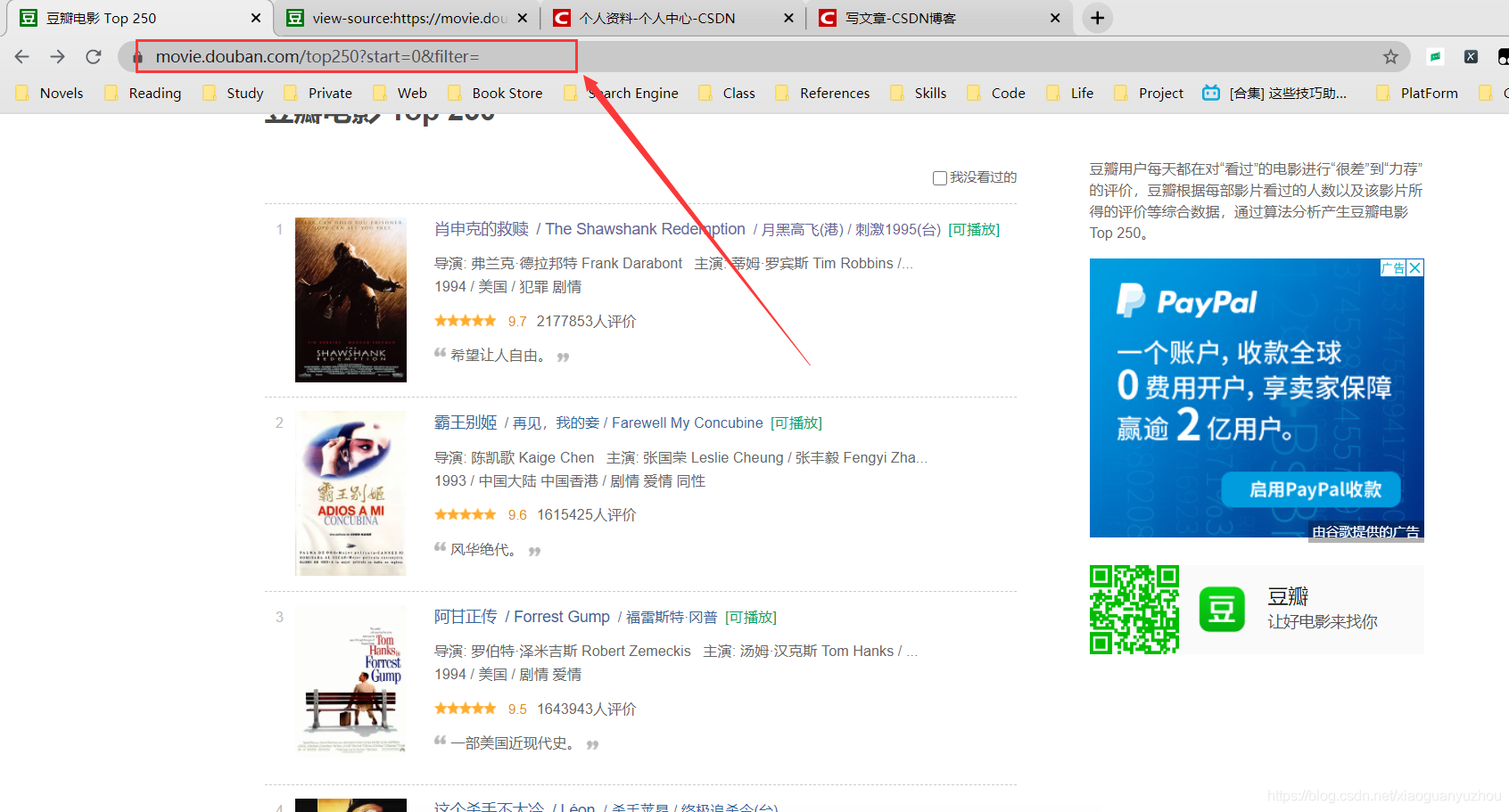
爬取过程
导入相关库
本次爬取过程中涉及到requests库,用于解析页面数据的lxml中的etree库以及将内容写入到excel文档中的xlwt库。如果没有相关库的朋友需要调出命令行,然后通过pip install 库名的方式进行安装。
import requests
from lxml import etree
import xlwt
#pip install requests
#pip install lxml
#pip install xlwt
页面内容的获取
通过requests库访问目标网页的数据,并确保能够获取到网页内容。
# 获取网页资源
def get_page_source(start_url,headers):response = requests.get(url=start_url,headers = headers)if response.status_code == 200:response.encoding = response.apparent_encodingpage_data = response.textreturn page_dataelse:return "未连接到页面"页面解析
获取到页面内容后,就是对页面内容进行解析,这里通过lxml库中的etree进行解析,然后用xpath语法进行对数据提取。
# 提取网页电影信息
def page_content(page_data):etree_data = etree.HTML(page_data)selector = etree_data.xpath('//*[@class="article"]/ol/li/div/div[2]')
数据提取
接下来我们就用xpath语法对解析过后的页面进行数据提取,分别提取电影名,评分,评论人数,以及每一部电影的标签或者寄语。
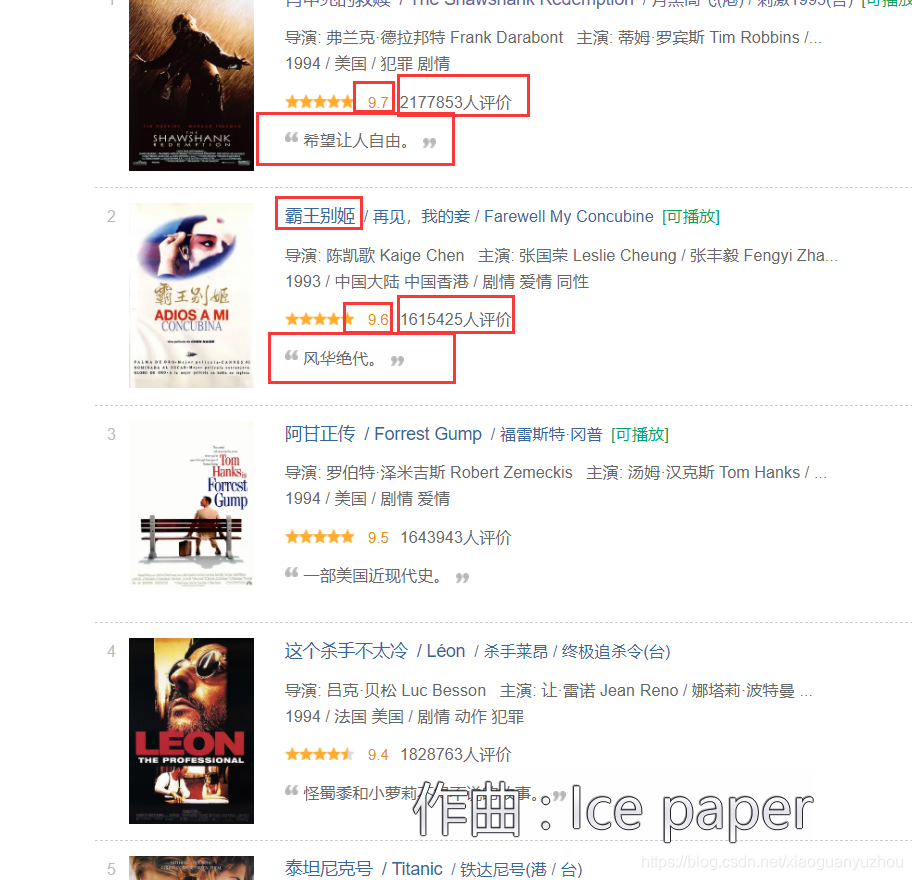
实现代码如下:
for item in selector:# 电影名称movie_names = item.xpath('./div/a/span[1]/text()')# print(movie_names)# 电影评分movie_scores = item.xpath('./div[2]/div/span[2]/text()')# print(movie_scores)# 电影评论人数movie_numbers = item.xpath('./div[2]/div/span[4]/text()')# print(movie_numbers)# 对电影的描述语quotes = item.xpath('./div[2]/p[2]/span/text()')# print(quotes)# 将每一行获取到的信息添加到一个电影的列表中one_movie_info_list = [movie_names,movie_scores,movie_numbers,quotes]# 将一个电影的列表添加到大的列表中movie_info_list.append(one_movie_info_list)
主函数的编写
函数调用
if __name__ == '__main__':for page in range(0,10):url = 'https://movie.douban.com/top250?start={}&filter='.format(str(page*25))# page += 25headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}get_page_source(start_url=url,headers=headers)page_content(get_page_source(start_url=url,headers=headers))
数据存储
#创建工作簿book = xlwt.Workbook(encoding='utf-8')#创建表单sheet = book.add_sheet('豆瓣排行250')#填写表头head = ['排名','电影名','评分','评价人数','电影寄语']# 写入表头for h in range(len(head)):sheet.write(0,h,head[h])# 排名for index in range(1,251):sheet.write(index,0,index)# 写入相对应的数据j = 1for data in movie_info_list:#从索引为第1行开始写k = 1for d in data:sheet.write(j,k,d)k += 1j += 1#退出工作簿并保存book.save('豆瓣电影Top250.xls')
完整代码
import requests
from lxml import etree
import xlwtmovie_info_list = []
# 获取网页资源
def get_page_source(start_url,headers):response = requests.get(url=start_url,headers = headers)if response.status_code == 200:response.encoding = response.apparent_encodingpage_data = response.textreturn page_dataelse:return "未连接到页面"# 提取网页电影信息
def page_content(page_data):etree_data = etree.HTML(page_data)selector = etree_data.xpath('//*[@class="article"]/ol/li/div/div[2]')# print(selector)for item in selector:# 电影名称movie_names = item.xpath('./div/a/span[1]/text()')# print(movie_names)# 电影评分movie_scores = item.xpath('./div[2]/div/span[2]/text()')# print(movie_scores)# 电影评论人数movie_numbers = item.xpath('./div[2]/div/span[4]/text()')# print(movie_numbers)# 对电影的描述语quotes = item.xpath('./div[2]/p[2]/span/text()')# print(quotes)# 将每一行获取到的信息添加到一个电影的列表中one_movie_info_list = [movie_names,movie_scores,movie_numbers,quotes]# 将一个电影的列表添加到大的列表中movie_info_list.append(one_movie_info_list)if __name__ == '__main__':for page in range(0,10):url = 'https://movie.douban.com/top250?start={}&filter='.format(str(page*25))# page += 25headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}t = get_page_source(start_url=url,headers=headers)page_content(t)#创建工作簿book = xlwt.Workbook(encoding='utf-8')#创建表单sheet = book.add_sheet('豆瓣排行250')#填写表头head = ['排名','电影名','评分','评价人数','电影寄语']# 写入表头for h in range(len(head)):sheet.write(0,h,head[h])# 排名for index in range(1,251):sheet.write(index,0,index)# 写入相对应的数据j = 1for data in movie_info_list:#从索引为第1行开始写k = 1for d in data:sheet.write(j,k,d)k += 1j += 1#退出工作簿并保存book.save('豆瓣电影Top250.xls')
结语
在编写过程中难免有需要改进的地方,如有更好的方法,或者有不同见解的地方,欢迎指出。