
爬蟲爬取網站之家,【Python爬蟲】用Python爬取娛樂圈排行榜數據
??想關注你的愛豆最近在娛樂圈發展的怎么樣嗎?本文和你一起爬取娛樂圈的排行榜數據,來看看你的愛豆現在排名變化情況,有幾次登頂,幾次進了前十名呀。 PS:在下一篇文章中分析排行榜的動態變化趨勢,并繪制成動態條形圖和折線圖。 ?? 一、網站

足球數據采集器,Java爬蟲——爬取體彩網足球賽果
現在用Python做爬蟲很是盛行,在學Java的本人尋思著Java如何做爬蟲。 本爬蟲例子為體育彩票網http://www.sporttery.cn/ 本例實現對“足球賽果開獎”的爬取;若要對體育彩票站其他頁面爬取,稍微修改代碼中URL規則即可;若要爬取非體彩網的其他網站&#

當當網爬蟲數據可視化,Scrapy爬蟲項目——阿里文學當當網
1. Cmd命令行創建項目 創建項目命令: scrapy startproject [項目名] Items定義要爬取的東西;spiders文件夾下可以放多個爬蟲文件;pipelines爬蟲后處理的文件,例如爬取的信息要寫入數據庫;settings項目設置 2. Scrapy常用模板 Scrapy-般通過
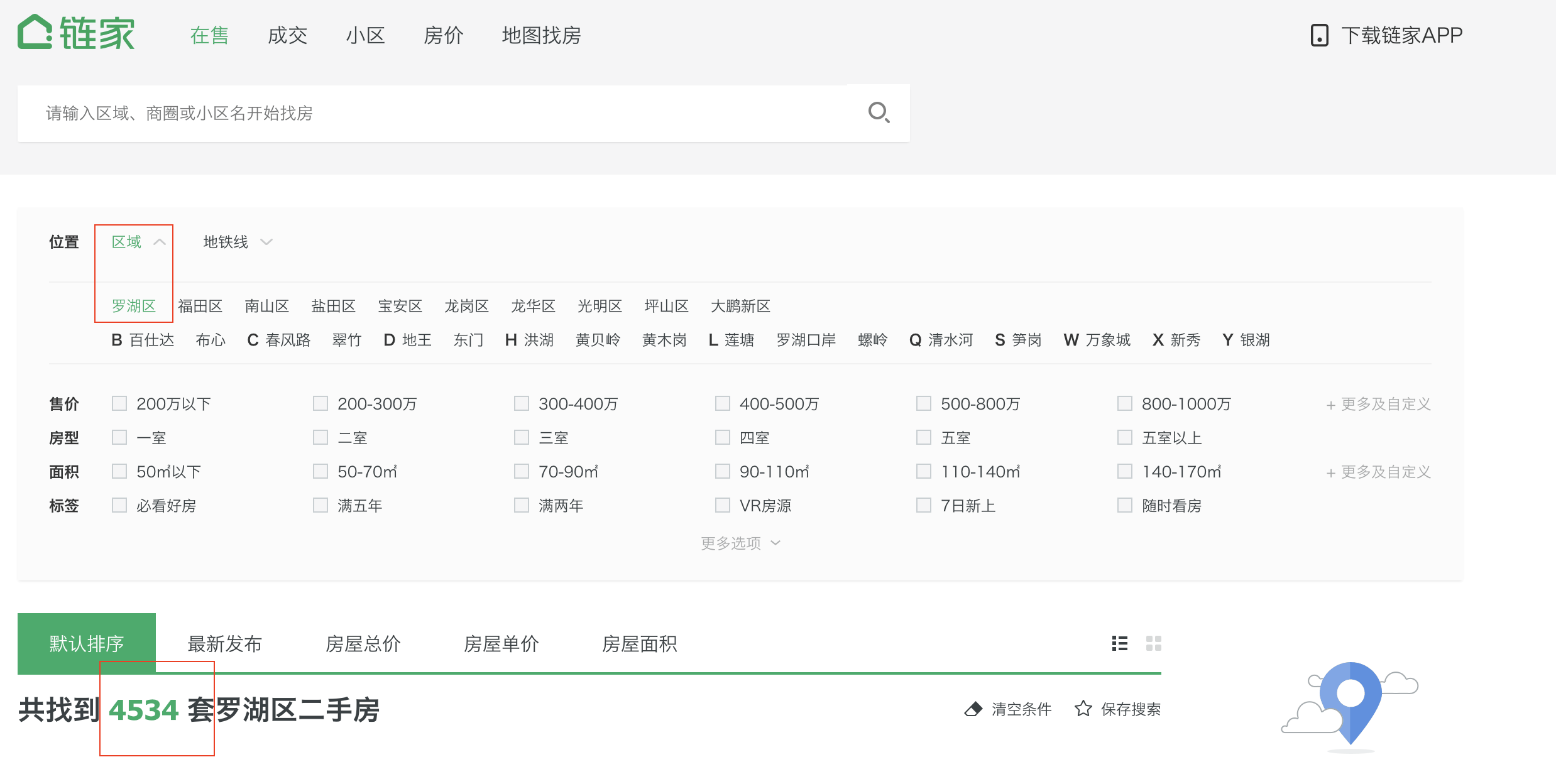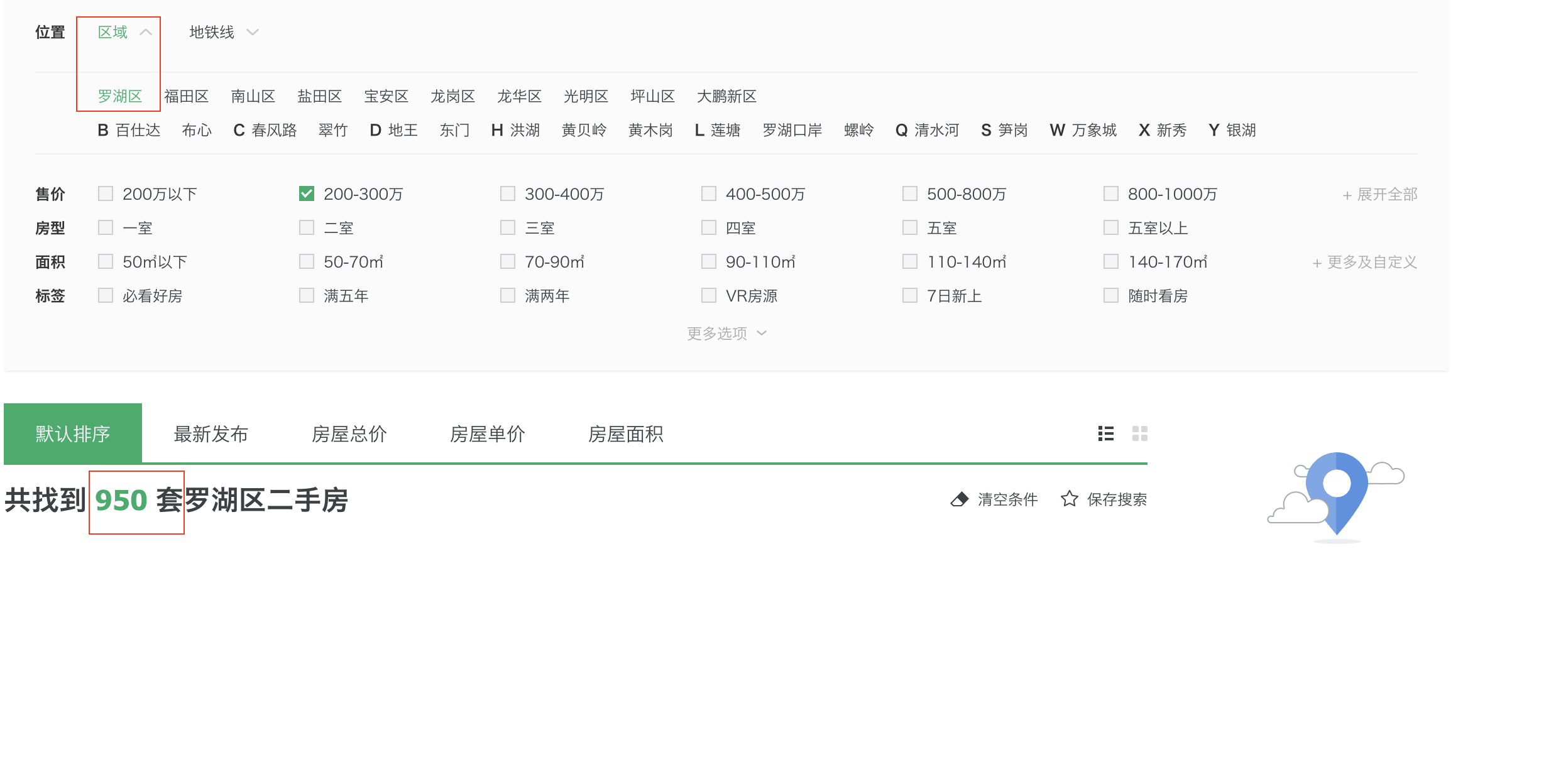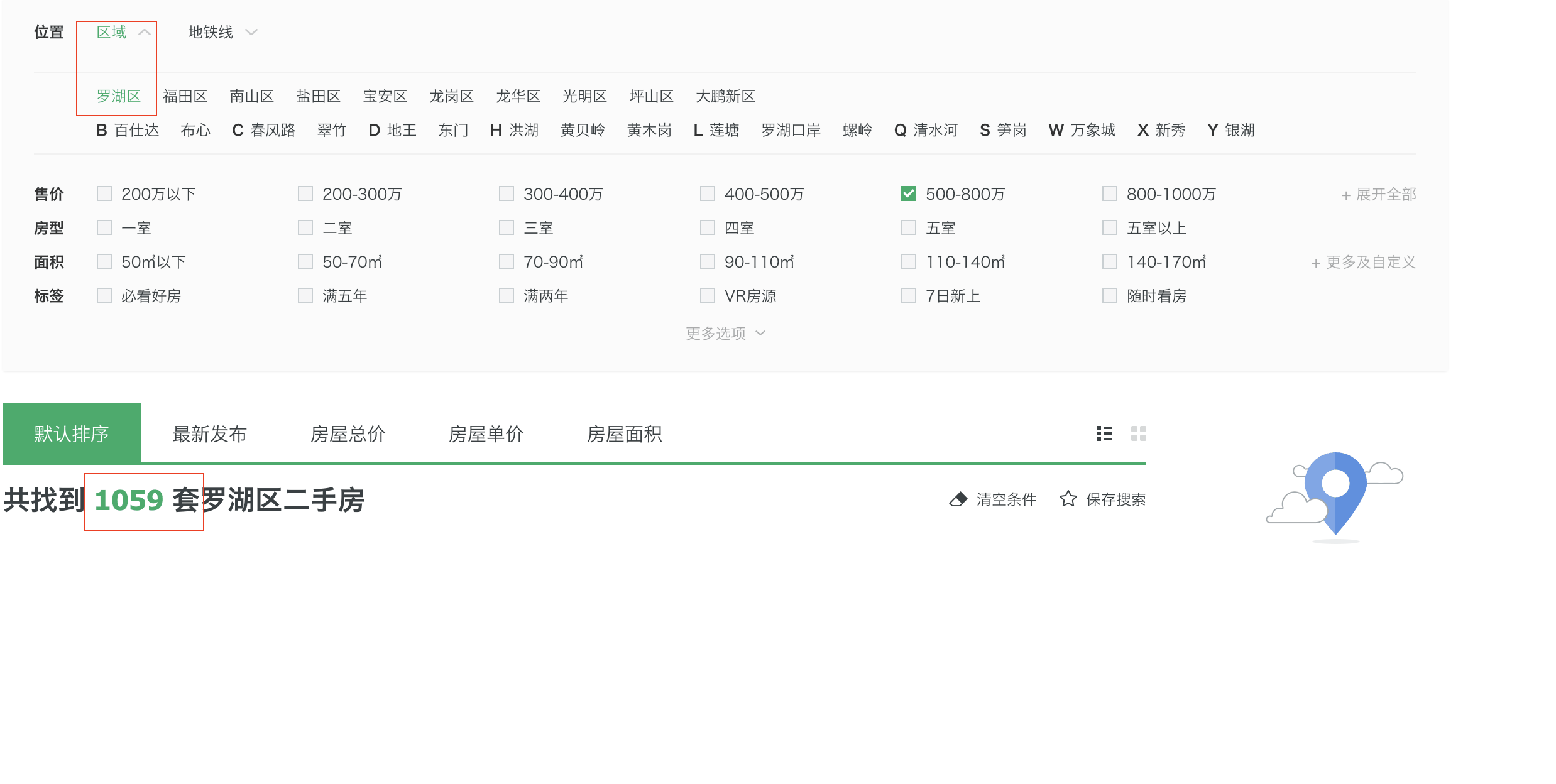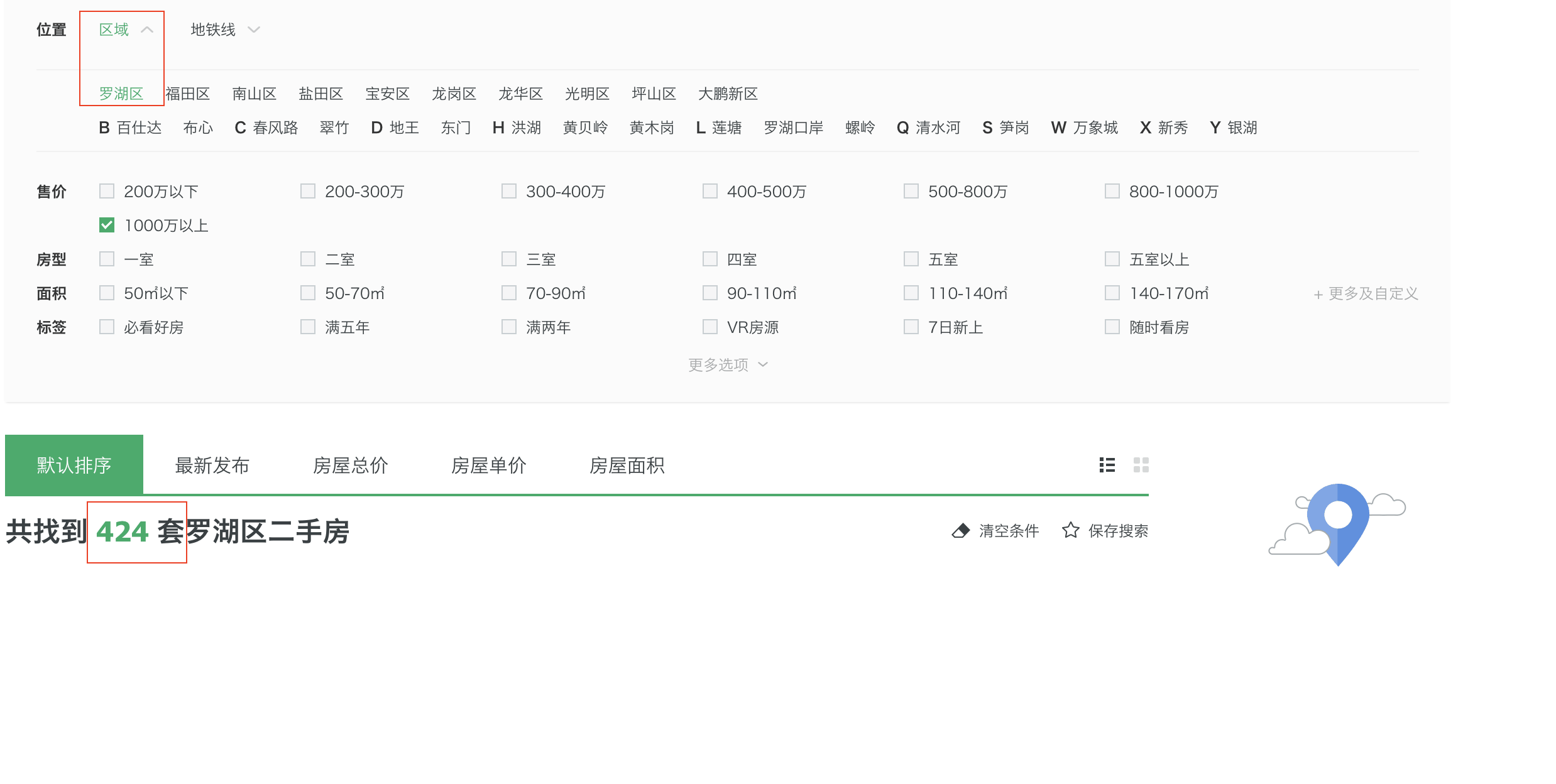
python爬蟲爬取新聞,爬蟲:一種打破3000套限制爬取所有鏈家二手房源的方法
本人在爬取二手房的時候,發現鏈家網站的每個鏈接(https://sz.lianjia.com/ershoufang/pg100/)最多只能有100頁,每頁30套房源,那么就是3000套。很多網友也遇到了類似的情況,卻沒有一種現行的解決方案,經過對頁面的探索,這里提出一種