用python刷網頁瀏覽量,用Python獲取公眾號閱讀數、點贊數。
最近利用了「新榜」和「壹伴」生成了自己的公眾號年報。對自己公眾號一年來的數據算是有所了解。比如總閱讀數、總點贊數。這里小F發現「新榜」和「壹伴」的數據居然不一樣。于是乎也想著自己去獲取公眾號數據,來統計一波。看一下準確的數據究竟是多少?主要用到

用python爬取網頁數據,Python干貨:教你如何利用python抓取微博評論,利用python知道更多微博大V有趣搞笑評論!
【Part1——理論篇】 試想一個問題,如果我們要去抓取某個微博大V微博的評論數據,應該怎樣去實現呢?最簡單的做法就是找到微博評論數據接口,然后通過改變參數來獲取最新數據并保存。首先尋找從微博抓取評論的接口,如下圖所示。 但是很不幸,

python如何檢索字符串中的特定字符,利用python抓取指定格式數據并翻譯
紀念我的第一個python動作 要實現的目標 給定properties文件,內容會有注釋匹配properties的value部分(“=”右邊的),翻譯出來value部分以.htm和.gif結尾的不需要翻譯文本中標簽和標簽中的內容不需要翻譯,翻譯出來的value替換原來的val

python爬取網站,python抓取表格數據_Python如何實現從PDF文件中爬取表格數據(代碼示例)
本篇文章給大家帶來的內容是關于Python如何實現從PDF文件中爬取表格數據(代碼示例),有一定的參考價值,有需要的朋友可以參考一下,希望對你有所幫助。 本文將展示一個稍微不一樣點的爬蟲。 以往我們的爬蟲都是從網絡上爬取數據,因為

python獲取周K線數據,python爬實時數據_如何用python爬取實時更新的動態數據?
爬蟲實時更新互聯網是絕對豪爽的數據源。不幸的是,倘若沒有輕易構制的CSV文獻可供下載和說明,則絕大部門。倘若要從很眾網站拘捕數據,則必要測驗舉辦收集抓取。倘若您照樣一個初學者,請不要憂愁-正在數據說明怎樣行使python中Beautiful Soup舉辦W

用python爬取網頁數據,python,抓取豆瓣電影,再也不用擔心沒有看不了的電影了
1. 豆瓣抓站流程 分析url特征(菜鳥階段)對需要抓取的數據設計正則表達式處理HTML中一些特征字符,換行符等 注意異常的處理和字符編碼的處理 2. 實現的功能 簡單的實現了抓取豆瓣電影Top100的電影名稱 3. 后期工作展望 抓取更多的有用數據(如:準確抓取導演, 抓取一個電影評論)使

Python爬取數據,爬取騰訊視頻網站數據
1 數據獲取 騰訊視頻的網站中隱含的是一個非結構化的數據。R語言的“XML”包中htmlParse和getNodeSet非常強大,通過htmlParse可以抓取頁面數據并形成樹狀結構,getNodeSet可以對抓取的數據根據XPath語法來選取特定的節點集合。“revst”包的html_nodes與html_att

python爬取網站,python抓取經典評論_通過Python抓取天貓評論數據
每日干貨好文分享丨請點擊+關注對商業智能BI、數據分析挖掘、大數據、機器學習感興趣的加微信tsbeidou,邀請你進入交流群。歡迎關注天善智能微信公眾號,我們是專注于商業智能BI,大數據,數據分析領域的垂直社區。天氣逐漸寒冷,覺得應該

python爬取網站,python新聞評論分析_使用 python 抓取并分析京東商品評論數據
本篇文章是python爬蟲系列的第三篇,介紹如何抓取京東商城商品評論信息,并對這些評論信息進行分析和可視化。下面是要抓取的商品信息,一款女士文胸。這個商品共有紅色,黑色和膚色三種顏色, 70B到90D共18個尺寸,以及超過700條的購買評
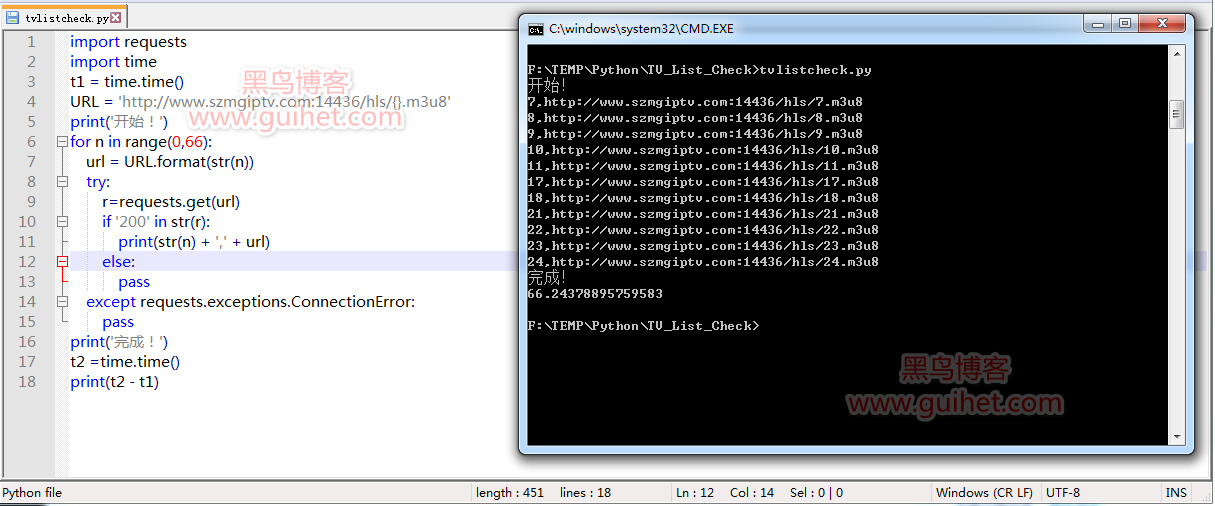
python源代碼怎么用,python抓取直播源 并更新_M3U8直播源有效性驗證Python版
M3U8格式的直播源一般都是通過http協議來實現的,其有效性檢測還是比較簡單的,一般情況,只要檢查這個源的地址是否可以正常連接即可,嚴謹點就是獲得返回的數據,查看m3u8文件內是否包含有效的播放地址.. 問題&解決方案 根據上一回掃源的
python爬蟲抓取數據的步驟,如何快速掌握Python數據采集與網絡爬蟲技術
云棲君導讀:本文詳細講解了python網絡爬蟲,并介紹抓包分析等技術,實戰訓練三個網絡爬蟲案例,并簡單補充了常見的反爬策略與反爬攻克手段。通過本文的學習,可以快速掌握網絡爬蟲基礎,結合實戰練習,寫出一些簡單的爬蟲項目。

python爬蟲抓取數據的步驟,如何快速掌握 Python 數據采集與網絡爬蟲技術
摘要: 本文詳細講解了 python 網絡爬蟲,并介紹抓包分析等技術,實戰訓練三個網絡爬蟲案例,并簡單補充了常見的反爬策略與反爬攻克手段。通過本文的學習,可以快速掌握網絡爬蟲基礎,結合實戰練習,寫出一些簡單的爬蟲項目。 本次

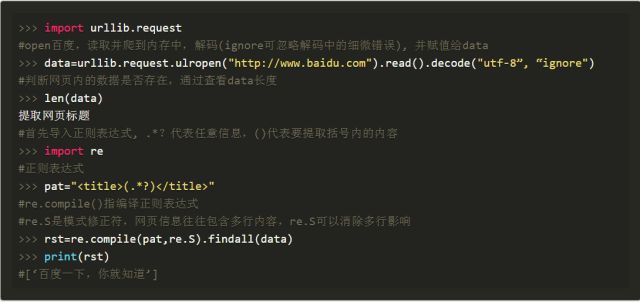
python爬取數據,python登錄網頁后抓取數據_Python抓取網頁數據的終極辦法
Pandas庫有一種內置的方法,可以從名為read_html()的html頁面中提取表格數據:https://pandas.pydata.org/import pandas as pdtables = pd.read_html("https://apps.sandiego.gov/sdfiredispatch/")print(tables[0])就這么簡單! Pandas可以在頁面上找到所有

python編程,python爬取王者_用Python爬取王者農藥英雄皮膚
0.引言 作為一款現象級游戲,王者榮耀,想必大家都玩過或聽過,游戲里中各式各樣的英雄,每款皮膚都非常精美,用做電腦壁紙再合適不過了。本篇就來教大家如何使用Python來爬取這些精美的英雄皮膚。 1.環境 操作系統:Windows / Linux p

python3,python爬取古詩文網站詩文一欄的所有詩詞
寫在前面 曾經,我們都有夢,關于文學,關于愛情,關于一場穿越世界的旅行,如今我們深夜飲酒,杯子碰在一起,都是夢破碎的聲音 曾經,面對詩文如癡如醉,而如今,已漠眼闌珊,風起云涌不再,嗚呼哀

python檢索文獻,使用python抓取落網期刊圖片
使用python抓取落網期刊圖片 雖然使用python開發也將近兩年了,但工作中使用python更多處理業務邏輯,數據加工等,難免有些枯燥、乏味。一直聽聞python在web數據爬取、數據分析上有無可比擬的優勢,于是抱著擴展下知識面,找點樂子的心理ÿ

Python爬取數據,用python爬取小說的總結_python如何使爬取的小說更利于觀看
python使爬取的小說更利于觀看的方法:1、使用追加模式將文章寫入txt文本關于文件的寫入, ‘w’ 的方式 是覆蓋寫, 沒有就創建, 那么我們寫小說就不需要用這個, 使用Python爬取數據?‘a’ 追加寫的模式, 然后添加適當的分隔符ÿ

python自動抓取網頁,python 基金凈值_用Python抓取天天基金網基金歷史凈值數據
請關注微信公眾號:金融數學 FinancialMathematics玩基金的朋友應該都深有體會,2018是相當慘淡的一年,尤其下半年,能夠保本就不錯了。2019迎來了開門紅,從2月11日到14日,連續四個交易日整體翻紅,“逢九必漲”,2019是不